我们蒋智威老师课题组在基于大语言模型的文本表示技术方面取得新进展:(1)针对大语言模型单向注意力导致的表示偏差,提出了免训练的词元前置方法,以让句子中的每个词元都可以捕捉到句子的完整语义;(2)针对大语言模型的句子嵌入仍然编码了大量语义无关的信息,提出了基于推断时干预的对比提示方法来捕捉句子的核心语义并提升句子嵌入的质量;(3)基于大语言模型对提示的敏感性,提出了多提示解码器框架来进行模型即服务的大模型的下游任务适配。
三项研究工作分别为:
1. Token Prepending: A Training-Free Approach for Eliciting Better Sentence Embeddings from LLMs
大语言模型往往采用单向注意力机制,即一个词元只能看到出现在它前面的词元而无法看到出现在它后面的词元,这导致了表示偏差进而影响了句子嵌入的表示质量。针对这一问题,该研究工作提出了一种词元前置的方法,即在输入Transformer前,把表示句子语义的词元前置使得句子中的每个词元都可以感知到句子的完整语义以避免表示偏差。通过经验性的探索,该研究工作发现仅在大语言模型的底层进行词元前置就可以有效地让所有词元感知到句子的完整语义。另外,该方法是即插即用且免训练的,也就是既可以跟之前的提示工程方法结合,使得开销轻量级,又可以保留大模型的通用能力。在多个大语言模型和多种任务上的大量实验验证了该提出方法的有效性。
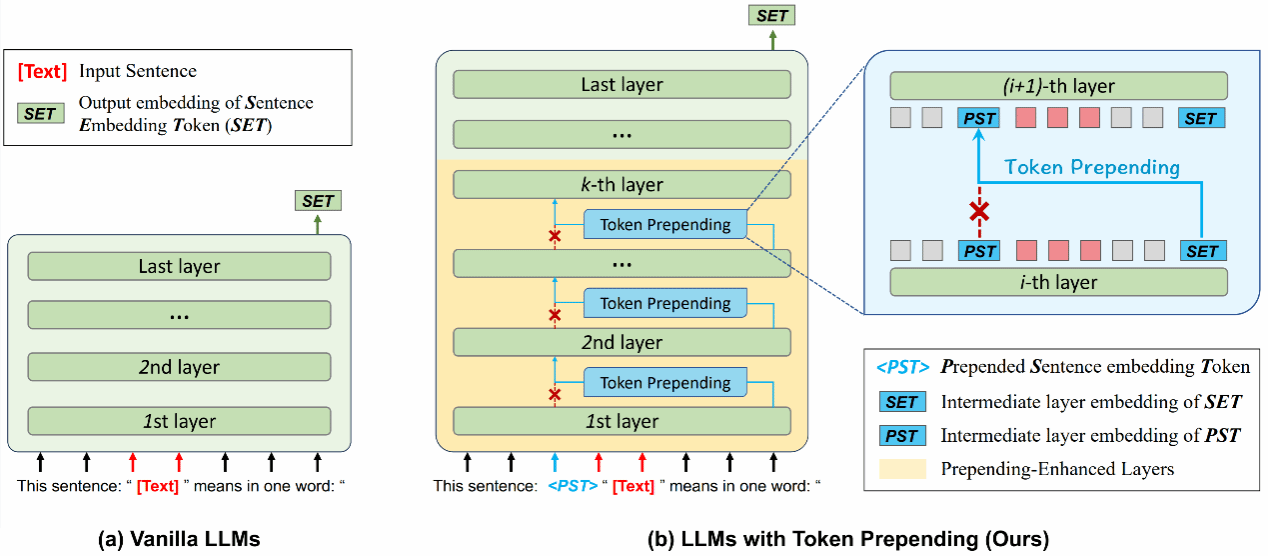
该研究工作相关成果已被自然语言处理领域顶级国际会议The 63rd Annual Meeting of the Association for Computational Linguistics(ACL 2025, CCF-A类会议)长文接收,欢迎对该研究感兴趣的同学和学术同行来信交流:jzw@nju.edu.cn。
2. Contrastive Prompting Enhances Sentence Embeddings in LLMs through Inference-Time Steering
之前的句子嵌入方法往往通过提示工程的方法来间接地让最后一个词元编码句子的核心语义。然而,通过解码实验,该研究工作发现句子嵌入仍然编码了大量无意义的非本质信息,比如a,the,is等。针对该问题,该工作提出了一种对比提示的方法。对比提示方法首先引入一个额外的辅助提示来编码句子中的非本质信息;之后,在大语言模型的某一层对比标准提示和辅助提示来消融掉标准提示中的非本质信息;最后,通过继续传播标准提示以获得核心语义相关的句子嵌入。由于该方法是即插即用的,所以其可以跟之前的提示工程方法结合。又因为该方法仅在推断时进行干预,所以大语言模型的通用能力不会被破坏。该提出方法的有效性在多个大语言模型和多种任务上得到了验证。
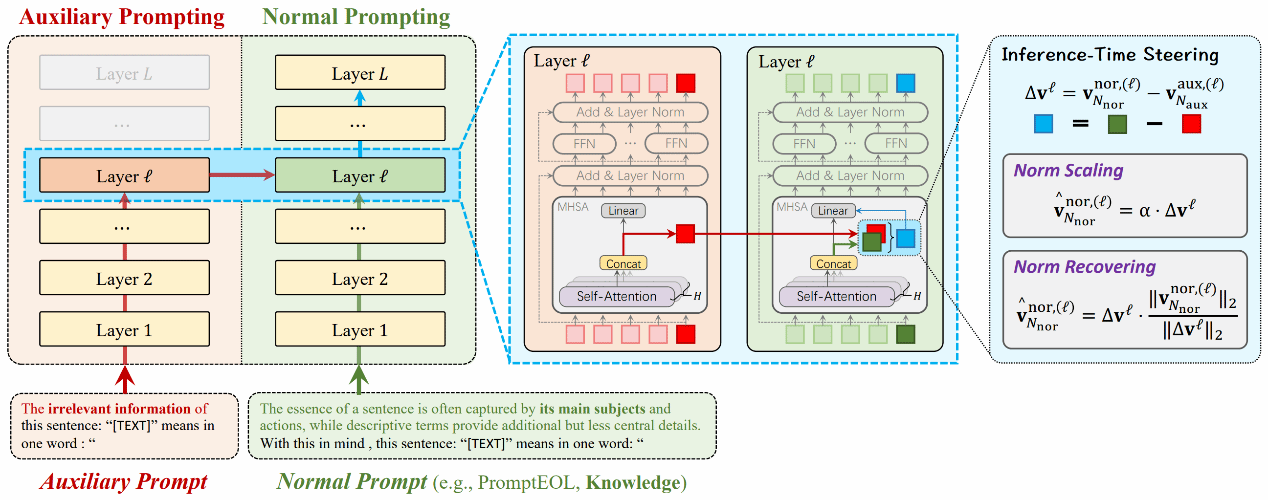
该研究工作相关成果已被自然语言处理领域顶级国际会议The 63rd Annual Meeting of the Association for Computational Linguistics(ACL 2025, CCF-A类会议)长文接收,欢迎对该研究感兴趣的同学和学术同行来信交流:jzw@nju.edu.cn。
3. Multi-Prompting Decoder Helps Better Language Understanding
随着大语言模型越来越大,大模型往往采用模型即服务Model-as-a-Service (MaaS)的方式部署在云端。在MaaS设置下,用户只能访问大模型的输出,即隐藏状态,词汇表输出,文本输出等内容,而无法访问大模型的参数和梯度。由于无法访问其参数和梯度,对模型即服务的大模型进行下游任务适应存在挑战。现有方法往往利用单个提示进行优化且大模型对提示是敏感的。考虑到这些问题,该研究工作提出了一种多提示解码器框架,可以同时考虑多个提示以进行下游任务适配。该框架包括基于最优传输的多提示解码和校准解码来分别解码输出的隐藏状态和词汇预测分布。该工作在公开的自然语言理解数据集上进行了大量实证研究,实验结果验证了该提出方法的有效性。
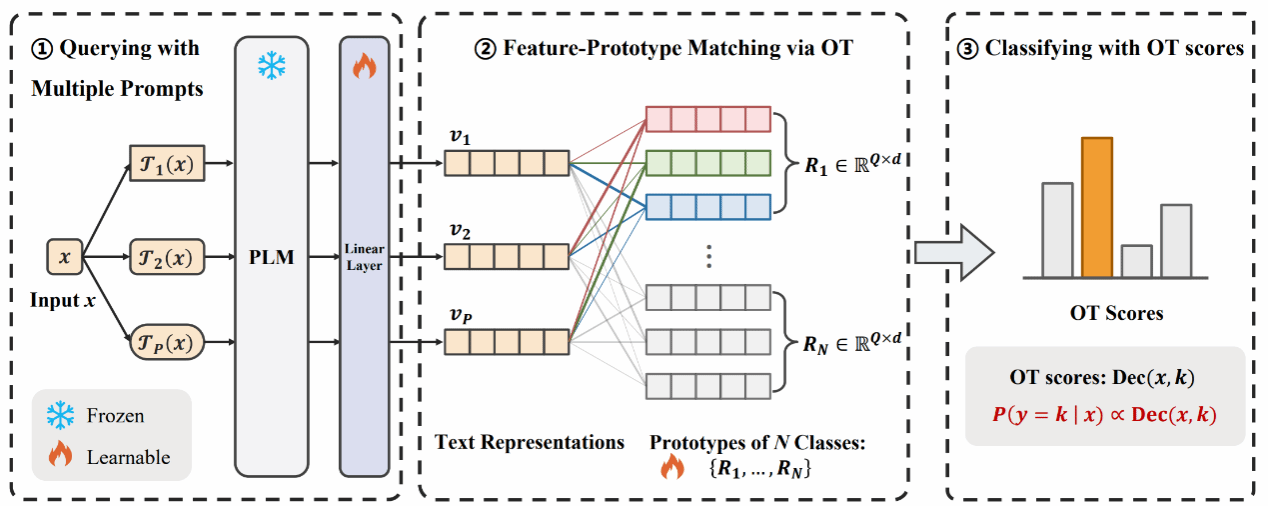
该研究工作相关成果已被自然语言处理领域顶级国际会议The 63rd Annual Meeting of the Association for Computational Linguistics(Findings of ACL 2025)接收,欢迎对该研究感兴趣的同学和学术同行来信交流:jzw@nju.edu.cn。


 English
English