大模型“炼丹”,已然成为AI时代最昂贵的“黑洞”之一。
动辄数月、上千张卡的训练周期,不仅是金钱的燃烧,更是对工程师耐心的极限考验。最让人头疼的是什么?不是模型不收敛,而是在漫长的训练过程中,性能曲线突然“抽风式”下跌,而你却像个“盲人摸象”的侦探,不知从何查起。
“是不是IO炸了?” “CPU瓶颈?” “还是哪个倒霉的节点网络堵了?”
面对复杂的软硬件堆栈,这种“玄学”式的优化,效率极低,成本极高。
现在,这个问题有了更优解。必威betway西汉姆联网站王智彬老师和田臣老师团队,联合华为等单位,拿出了他们的答案。在7月7日于波士顿举行的USENIX ATC 2025大会上,该团队的长文论文正式发表,带来一套面向昇腾芯片的大模型训练性能诊断与优化系统——Hermes。
这套系统源于团队3年、面向40多个客户、解决223个性能问题、沉淀135个关键案例的真实战场经验,目标只有一个:
将大模型在国产昇腾(Ascend)芯片上的训练优化,从“玄学”变为“科学”。
尤为值得一提的是,这也是 USENIX ATC 的最后一届。
作为系统领域曾经最硬核的舞台之一,这一收官之作,也多了一层纪念与致敬的意味。
论文地址:https://www.usenix.org/conference/atc25/presentation/zhou
告别“盲人摸象”,AI训练呼唤“智能医生”
在 Hermes 诞生之前,昇腾芯片上的模型优化主要面临三座大山:
想“体检”,先“减寿”:传统的性能剖析工具,就像一台笨重的CT机。想做个全身检查?可以,但代价是训练性能先掉一半,甚至还得停机重启才能配置。对于长周期任务,这完全无法接受。
“头痛医头”,治标不治本:市面上的分析工具往往只盯着一个点,比如专门看 I/O,或者只分析 RDMA 网络。但实际情况是,瓶颈之间环环相扣。通信慢了,根子可能在计算负载不均;计算慢了,原因可能出在 CPU 的算子编译上。这种“片面诊断”很难找到病根。
药方一堆,不知用哪个:面对几十种优化策略,到底该用哪个?全靠“老师傅”的经验“一把梭”?这种方式不仅成功率低,而且无法规模化复制。
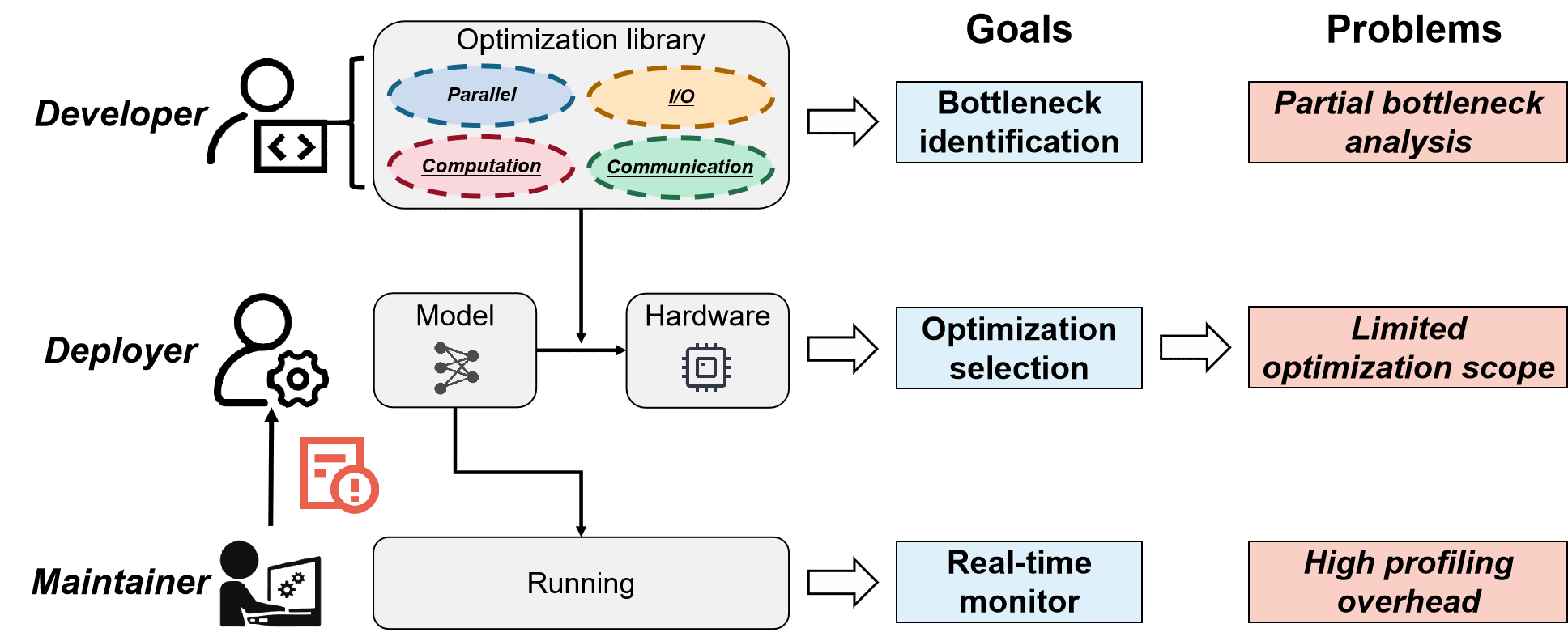
Hermes 要做的,就是成为一名经验丰富、工具先进的“AI训练智能医生”。
三步“望闻问切”,揪出性能元凶
Hermes 的核心是一套“分层瓶颈分析”框架,它像一位严谨的医生,通过三步定位病灶。
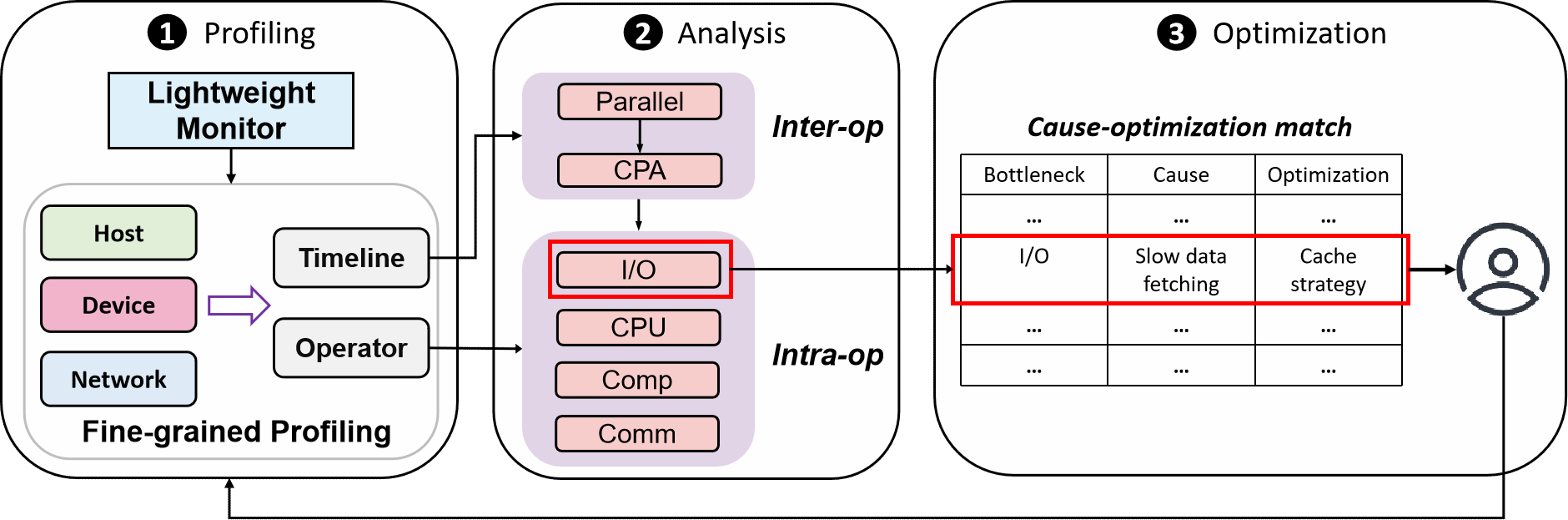
第一步:“普查”——轻量级动态剖析,发现异常
Hermes 不会一上来就进行地毯式搜查。它先用一个开销极低的轻量级监控器,对整个训练集群进行实时“普查”。一旦发现某个节点的性能指标(如吞吐量)出现异常波动,系统会立刻标记出“问题设备”和“问题步骤”,并动态触发下一步的细粒度检查,全程无需中断训练。
第二步:“会诊”——分层分析,从宏观到微观
找到问题节点后,Hermes 开始进行“专家会诊”。
算子间“全局会诊”:首先,从宏观视角分析 Host、Device、Network 三大组件的并行效率(Overlap Ratio)和关键路径。判断问题是出在“团队协作”不畅(并行度低),还是某个“核心成员”拖后腿(关键算子耗时长)。
算子内“专科诊断”:定位到具体的瓶颈算子后,Hermes 会像专科医生一样,深入其内部,从 I/O、CPU、计算、通信四个维度进行精细化诊断。比如,通过分析数据队列状态来判断I/O瓶颈是读数据慢、预处理慢还是CPU到NPU传输慢导致的;通过 Roofline 模型判断是计算单元摸鱼(Underutilization)还是被算力或者内存带宽卡了脖子。
第三步:“开方”——经验匹配,给出精准药方
诊断完成,如何“开药”?这正是 Hermes 的精髓所在。
团队将 135 个关键案例的优化经验,全部沉淀为一个名为 mstt advisor 的智能优化顾问。
这个顾问就像一位经验丰富的“老中医”,它的知识库里存放着一张巨大的“病症-药方”匹配表。当分析出具体病因后,例如“HCCS通信数据未对齐”或“动态 Shape 算子导致反复编译”,它能立刻从知识库中匹配出经过验证的最优解决方案,并生成一份清晰的 HTML 优化报告,告诉你具体该怎么改。
上车实战:从盘古到 MoE,加速效果拉满
理论说再多,不如看疗效。Hermes 在多个真实大模型训练任务中,交出了惊艳的成绩单:
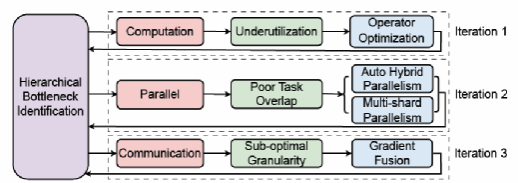
128卡百亿盘古大模型训练,直接提速 3.05 倍!通过三轮“诊断-优化”迭代,Hermes 帮助盘古模型先后解决了计算、并行、通信三大瓶颈,总训练时长从 2856 小时骤降至 936 小时。
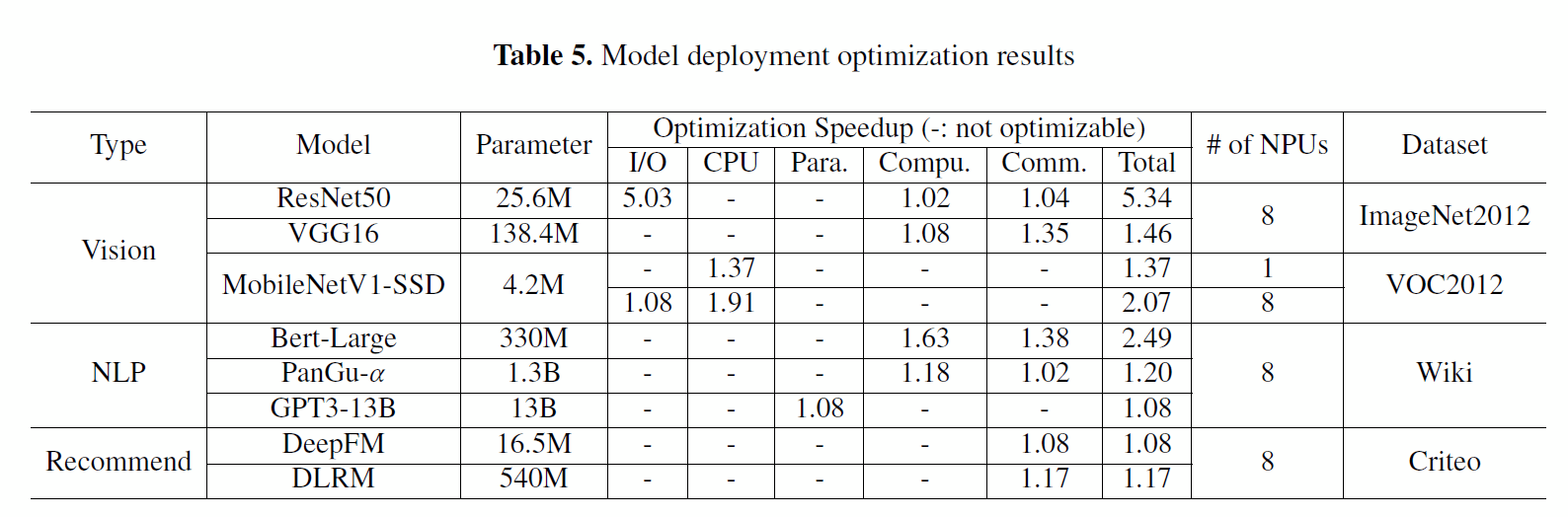
十余种模型部署优化,性能提升1.08-5.34 倍不等!其中在MobileNetV1模型从 GPU 迁移到昇腾 NPU 的场景中,Hermes 精准找出了多个 CPU 和 I/O 瓶颈,优化后性能追平GPU 的 90%。
9000 卡 MoE 集群“疑难杂症”,被轻松拿捏!面对超大规模集群中由 GC(垃圾回收)和硬件故障引发的随机性性能暴跌,Hermes 成功定位并指导修复,平均吞吐提升 1.19 倍,训练稳定性大幅增强。
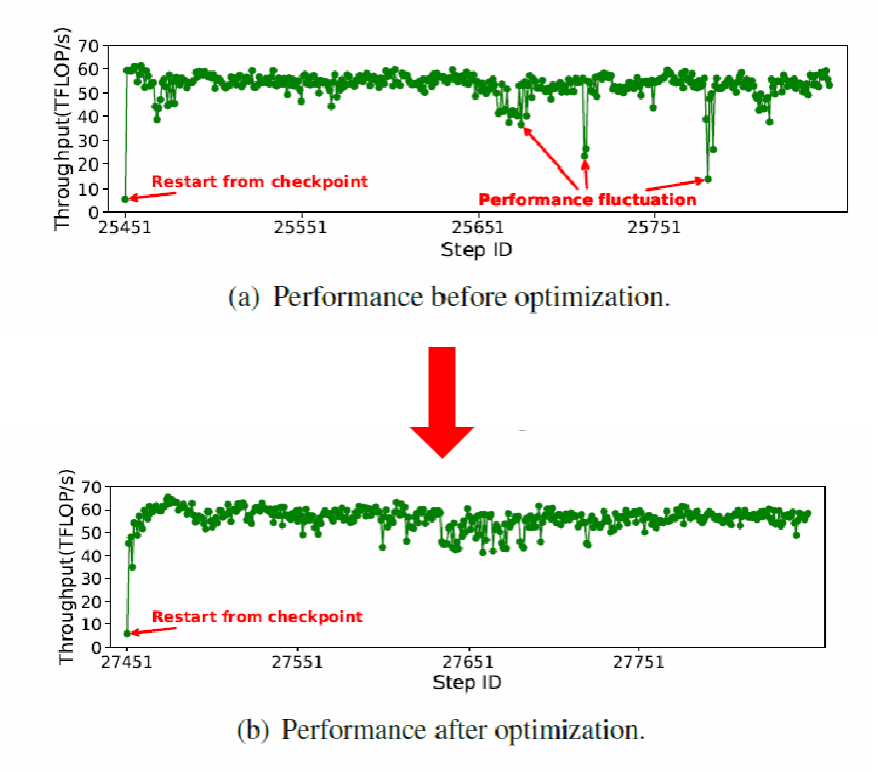
可以说,Hermes 的出现,为国产大模型“开得快”,更要“跑得稳”,提供了一套强有力的系统级保障。
欢迎对大模型训练/推理性能分析和优化感兴趣的老师和同学联系交流:wzbwangzhibin@gmail.com


 English
English